 Laurence Bank
Laurence Bank
On Optimizing Open Source Projects
(The TL;DR version of this for those who just want the code, grab the fork here)
Why optimize? Software is more of an art than a science. In software, there are a variety of programming languages and within each there are nearly an infinite number of ways to solve the same problem with different code. Solving the same problem on the same hardware with different solutions uses different amounts of time (and energy). The difference can be dramatic and when millions (billions?) of people are using the same software every day, the impact can be measured in productivity, dollars or pollution avoided. Computers are not like a wood fireplace where the wood burns the same whether you make use of the heat or not. Computers do work on demand and sleep (use less energy) when not in use. The faster the work can get done, the more time can be spent sleeping or the quicker the next task can begin.
The internet is run on mostly open source code. Some of this code has been painstakingly optimized, but unfortunately much has not. Code optimization is a specialized set of skills that most software developers don’t possess. It’s not practical or even feasible to fully optimize every project / library / tool in use today; there’s just too much code and not enough skilled people to dedicate to such a task. It is beneficial when some low hanging fruit is discovered that benefits a lot of people from a small investment of time. One such open source tool that we use in our image optimization service is MozJPEG. Optimal performance is critical for our customers and the environment, so we took some time to examine if there was room for optimization.
MozJPEG
Mozilla created MozJPEG as a drop-in replacement for libjpeg-turbo. The purpose is to improve JPEG compression so that the resulting files are smaller, yet retain the same quality. The project was created with the intention of allowing websites to use less bandwidth to deliver their graphics. I’m not going to go into the details of how it works because this blog post is about something else entirely. The tradeoff of creating smaller files is that MozJPEG uses a lot more CPU time (energy) compared to libjpeg-turbo – https://libjpeg-turbo.org/About/Mozjpeg. The extra computational effort is certainly worth it if you’re creating images that get “written once and read many times”.
One aspect of this slower performance is that most people will assume that the loss of speed is a necessary consequence of using a more advanced algorithm. This is true; MozJPEG is doing a lot more work to create smaller files compared to libjpeg. I’ve learned over the years that it’s best not to assume anything about code and better still to test. I myself had been complacent for quite a while with my use of MozJPEG and was treating it like a black box. Out of curiosity I decided to run it in a profiler (a tool which shows specifically where time is spent inside of software) and discovered a loop in the forward_DCT stage that was taking a lot of time to execute. I searched Github for the history of that code and found that a check-in which fixed a quality bug had the unintended consequence of hurting the performance. This change occurred 6+ years ago:
https://github.com/mozilla/mozjpeg/commit/ea4fad9aece1d7abc083c598e8b464cdc8e2ea11
If the original author had measured the runtime of his new code, he would have discovered that encoding images took noticeably longer compared to before the change. The loop in question looks like this:

It looks innocent enough, but two things that it’s doing create bottlenecks on the CPU: integer division and a conditional statement/branch. The purpose of the code is to scale the DCT coefficients differently depending on their position within the 8×8 block. The aanscales[] array contains integer values used to scale the integer coefficients by a fractional amount (e.g. 1.25) by multiplying by 32768 and then dividing by the value from the table. The problem is that division on computers (both integer and floating point) is a relatively slow operation. Where most instructions can execute in a single clock cycle on modern CPUs, a division can take more than 100 cycles depending on the value. There is no practical shortcut to accomplish division, so even the most advanced and modern CPUs still execute ‘DIV’ in many more clock cycles than other math instructions. The other problem with the loop is the conditional statement which treats negative values differently from positive ones. It appears to do this to make sure that rounding occurs away from 0. This condition can require a branch on some CPUs and a conditional load on others. Both situations create a hiccup in the CPU’s execution pipeline because it must wait for the result of the compare before it can proceed.
My first thought was to create a better implementation in C so that the compilers of various target CPUs could create optimized code from that. I modified the scale factors to be the inverse situation – multiply by the scale factor and shift right by a power of 2. Multiplication and shift operations are both very fast on all modern CPUs. The auto-vectorizer of x64-Clang was able to generate good SIMD code with the build flags of the MozJPEG project, but for some reason the same project failed to create SIMD code on the Arm M1. Here’s the improved C code:
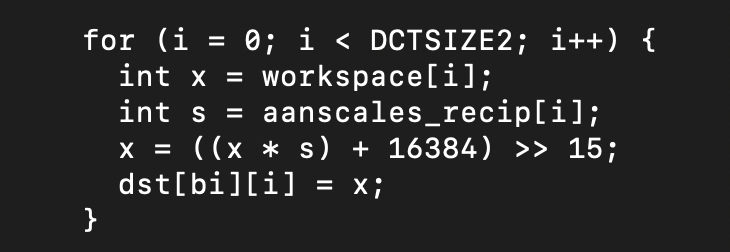
This new loop removes the divide instruction and the comparison.The rounding behavior is the same as the original. The original scaling table has been replaced by one which has the integer reciprocals instead. The output generated by the new code is identical to the original so there’s no downside to this improvement.
How many other open source projects could benefit from someone taking the time to profile them?
The Proposition
Most people are aware of bug bounties – rewards offered for finding vulnerabilities in software. How about a new type of bounty offered for finding (and possibly fixing) performance problems? It’s certainly easier to see and correct performance problems in open source projects, but it’s also possible to find them in closed source projects. Profilers can be attached to running processes on most operating systems and allow you to see system calls by name and the assembly language instructions of code taking a lot of processor time. These days a lot of processes are running ‘in the cloud’ and time is money. You should be able to draw a straight line from how fast your code runs to how much it costs you per month. If you know how much it costs to run it, then you also know how valuable a speed improvement would be.
An example of a performance problem I found in a closed source tool is memory ‘mis-management’. The profiler showed that the inner loop of the main process was furiously allocating and freeing memory during a normal session using the software. If malloc() and free() show up on the profile as taking a significant amount of time, the code is doing something wrong. Another example that’s easy to spot – a program abusing disk I/O by reading or writing in tiny chunks. These are the kinds of problems that can sink performance, but can be easily missed by the original authors.
Lessons Learned
- A significant amount of CPU time could have been saved if this problem had been discovered sooner
- The performance degradation could have been caught immediately if a performance test was part of the normal regression tests.
- A small code change can have a large impact on the performance
- It’s worth profiling popular back-end software that’s mostly hidden from view
- Never assume you’re stuck with the performance you’ve got
Result
We’ve observed performance improvements between 10-30% with binary-identical output to the original MozJPEG. We didn’t spend all that much time benchmarking it – feel free to do so yourself! Given the number of times we execute the code on a daily basis, every little helps and we’re more than happy with the result.
Grab the snappier fork of mozjpeg here:

mozjpeg (this link opens in a new window) by kraken-io (this link opens in a new window)
Improved JPEG encoder.
About the author
Larry is a software performance fanatic who gets his thrills making software go faster. He also enjoys tinkering with embedded devices because the memory and speed constraints add to the fun. You can follow him on twitter to see all of his latest crazy projects. Follow him on Twitter at @fast_code_r_us.
About Kraken.io
Kraken.io is an image optimization and compression SaaS platform with additional manipulation capabilities such as image resizing. Our goal is to automatically shrink the byte size of images as much as possible, while keeping the visual information intact, and of consistently high quality such that results never need to be manually checked for fidelity. Follow us on Twitter at @KrakenIO
